
图解 ArrayDeque 比 LinkedList 快
- 如果评论区没有及时回复,欢迎来公众号:ByteCode 咨询
- 公众号:ByteCode。致力于分享最新技术原创文章,涉及 Kotlin、Jetpack、算法、译文、系统源码相关的文章
在之前的两篇文章中主要分析了 Java 栈的缺点 ,为什么不推荐使用 Java 栈 ,以及 为什么不推荐直接使用 ArrayDeque 代替 Java Stack 。更多内容点击下方链接前去查看。
接口 Deque 的子类 ArrayDeque ,作为栈使用时比 Stack 快,因为原来的 Java 的 Stack 继承自 Vector,而 Vector 在每个方法中都加了锁,而 Deque 的子类 ArrayDeque 并没有锁的开销。
接口 Deque 还有另外一个子类 LinkedList。LinkedList 基于双向链表实现的双端队列,ArrayDeque 作为队列使用时可能比 LinkedList 快。
而这篇文章主要来分析,为什么 ArrayDeque 比 LinkedList 快。在开始分析之前,我们需要简单的了解一下它们的数据结构的特点。
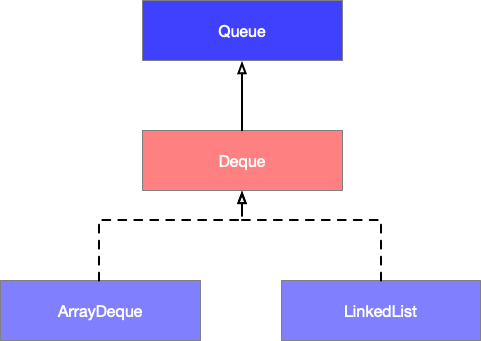
接口 Deque
接口 Deque 继承自 Queue 即队列, 在 Java 中队列有两种形式,单向队列( AbstractQueue ) 和 双端队列( Deque ),单向队列效果如下所示,只能从一端进入,另外一端出去。

而今天主要介绍双端队列( Deque ), Deque 是双端队列的线性数据结构, 可以在两端进行插入和删除操作,效果如下所示。

双端队列( Deque )的子类分别是 ArrayDeque 和 LinkedList,ArrayDeque 基于数组实现的双端队列,而 LinkedList 基于双向链表实现的双端队列,它们的继承关系如下图所示。
接口 Deque 和 Queue 提供了两套 API ,存在两种形式,分别为抛出异常,和不抛出异常,返回一个特殊值 null 或者布尔值 ( true | false )。
| 操作类型 | 抛出异常 | 返回特殊值 |
|---|---|---|
| 插入 | addXXX(e) | offerXXX(e) |
| 移除 | removeXXX() | pollXXX() |
| 查找 | element() | peekXXX() |
ArrayDeque
ArrayDeque 是基于(循环)数组的方式实现双端队列,数组初始化容量为 16(JDK 8),结构图如下所示。
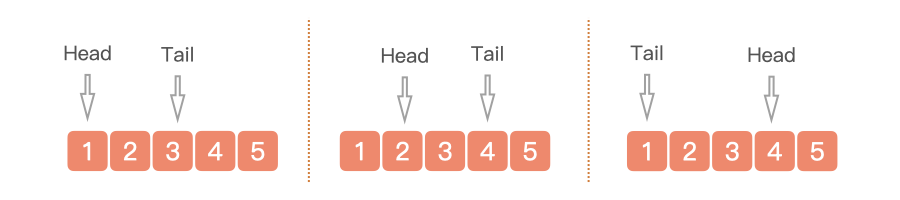
ArrayDeque 具有以下特点:
- 因为双端队列只能在头部和尾部插入或者删除元素,所以时间复杂度为
O(1),但是在扩容的时候需要批量移动元素,其时间复杂度为O(n) - 扩容的时候,将数组长度扩容为原来的 2 倍,即
n << 1 - 数组采用连续的内存地址空间,所以查询的时候,时间复杂度为
O(1) - 它是非线程安全的集合
LinkedList
LinkedList 基于双向链表实现的双端队列,它的结构图如下所示。
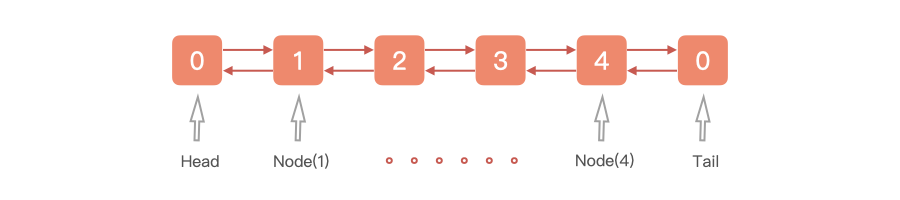
LinkedList 具有以下特点:
LinkedList是基于双向链表的结构来存储元素,所以长度没有限制,因此不存在扩容机制- 由于链表的内存地址是非连续的,所以只能从头部或者尾部查找元素,查询的时间复杂为
O(n),但是 JDK 对LinkedList做了查找优化,当我们查找某个元素时,若index < (size / 2),则从head往后查找,否则从tail开始往前查找 , 但是我们在计算时间复杂度的时候,常数项可以省略,故时间复杂度O(n)
Node<E> node(int index) { |
- 链表通过指针去访问各个元素,所以插入、删除元素只需要更改指针指向即可,因此插入、删除的时间复杂度
O(1) - 它是非线程安全的集合
最后汇总一下 ArrayDeque 和 LinkedList 的特点如下所示:
| 集合类型 | 数据结构 | 初始化及扩容 | 插入/删除时间复杂度 | 查询时间复杂度 | 是否是线程安全 |
|---|---|---|---|---|---|
| ArrqyDeque | 循环数组 | 初始化:16 扩容:2 倍 |
0(n) | 0(1) | 否 |
| LinkedList | 双向链表 | 无 | 0(1) | 0(n) | 否 |
为什么 ArrayDeque 比 LinkedList 快
了解完数据结构特点之后,接下来我们从两个方面分析为什么 ArrayDeque 作为队列使用时可能比 LinkedList 快。
从速度的角度:
ArrayDeque基于数组实现双端队列,而LinkedList基于双向链表实现双端队列,数组采用连续的内存地址空间,通过下标索引访问,链表是非连续的内存地址空间,通过指针访问,所以在寻址方面数组的效率高于链表。从内存的角度:虽然
LinkedList没有扩容的问题,但是插入元素的时候,需要创建一个Node对象, 换句话说每次都要执行new操作,当执行new操作的时候,其过程是非常慢的,会经历两个过程:类加载过程 、对象创建过程。类加载过程
- 会先判断这个类是否已经初始化,如果没有初始化,会执行类的加载过程
- 类的加载过程:加载、验证、准备、解析、初始化等等阶段,之后会执行
<clinit>()方法,初始化静态变量,执行静态代码块等等
对象创建过程
- 如果类已经初始化了,直接执行对象的创建过程
- 对象的创建过程:在堆内存中开辟一块空间,给开辟空间分配一个地址,之后执行初始化,会执行
<init>()方法,初始化普通变量,调用普通代码块
接下来我们通过 算法动画图解 | 被 “废弃” 的 Java 栈,为什么还在用 文章中 LeetCode 算法题:有效的括号,来验证它们的执行速度,以及在内存方面的开销,代码如下所示:
class Solution { |
正如你所看到的,核心算法都是一样的,通过接口 Deque 来访问,只是初始化接口 Deque 代码不一样。
// 通过 LinkedList 初始化 |

结果如上所示,无论是在执行速度、还是在内存开销上 ArrayDeque 的性能都比 LinkedList 要好。
如果有帮助 点个赞 就是对我最大的鼓励
代码不止,文章不停
欢迎关注公众号:ByteCode,持续分享最新的技术
- 本文作者:hi-dhl
- 本文标题:图解 ArrayDeque 比 LinkedList 快
- 本文链接:https://hi-dhl.com/2021/09/27/algorithm/03-arraydeque2/
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 hi-dhl
